今天我們會展示以抓取新聞為外部資料源,並且用OpenAI的embeddingmodel將資料源轉成向量存入本地的向量資料庫,接著再將使用者詢問的問題,進行資料庫的查詢後,放入提示,再由LLM進行回答。
pip install langchain langchain_community langchain_chroma
pip install bs4

# 1. Create model
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "你的OpenAI API key"
model = ChatOpenAI(model="gpt-4o")
embeddingmodel = OpenAIEmbeddings(model="text-embedding-ada-002")
import bs4
from langchain_community.document_loaders import WebBaseLoader
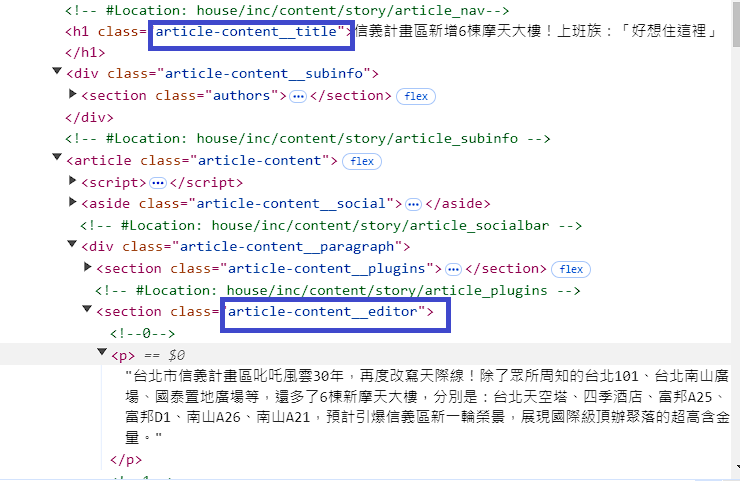
# 2. 抓取網頁的特定class的內容,並載入
loader = WebBaseLoader(
web_paths=("https://house.udn.com/house/story/123590/7815040",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("article-content__title",
"article-content__editor")
)
),
)
docs = loader.load()
上一步驟載入的檔案包含多種資訊,但我們只需要其中的page_content(文件內容)
另外輸出文件長度和chunk長度,文件的長度有可能過長,導致模型很難利用上下文去判斷
chunk_size, chunk_overlap 是最主要調整的屬性,可以根據文件長度進行調整
chunk_size代表chunk長度
chunk_overlap,表示切割的chunk之間字元的重疊數量,降低語句和其他重要的上下文分開機會
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 3. 切分成數個chunk
all_text = "".join(doc.page_content for doc in docs)
print("文件長度: ", end="")
print(len(all_text))
print("chunk長度: ", end="")
chunk_size = 300
print(chunk_size)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=50)
splits = text_splitter.split_documents(docs)
from langchain_chroma import Chroma
# 4. 轉換成embedding,儲存進Chroma向量資料庫.
vectorstore = Chroma.from_documents(
documents=splits, embedding=embeddingmodel)
retriever = vectorstore.as_retriever()
retriever為何要配合format_docs的原因
retriever從向量資料庫中,搜尋到最相似的片段後(docs),但包含其他非文件內容的資訊,
將這些片段當成參數輸入給format_docs,格式化成字串
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# 5. 做成chain.
template = """使用以下的上下文來回答最後的問題。
如果你不知道答案,就直接說你不知道,不要編造答案。
最多用三句話,並保持回答簡明扼要。
回答結束時,總是要說「感謝提問!」
{context}
使用者提供的額外資訊:
{user_input}
"""
custom_rag_prompt = PromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "user_input": lambda x: x}
| custom_rag_prompt
| model
| StrOutputParser()
)
小提醒,rag_chain.invoke之後,會送至lambda函數的x變數,但lambda x: x則表示保持原樣,傳入到prompt之中
# 6. 呼叫
result = rag_chain.invoke("新增哪6棟摩天大樓?")
print(result)
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import os
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# 1. Create model
os.environ["OPENAI_API_KEY"] = "你的OpenAI API key"
model = ChatOpenAI(model="gpt-4o")
embeddingmodel = OpenAIEmbeddings(model="text-embedding-ada-002")
# 2. 抓取網頁的特定class的內容,並載入
loader = WebBaseLoader(
web_paths=("https://house.udn.com/house/story/123590/7815040",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("article-content__title",
"article-content__editor")
)
),
)
docs = loader.load()
# 3. 切分成數個chunk
all_text = "".join(doc.page_content for doc in docs)
print("文件長度: ", end="")
print(len(all_text))
print("chunk長度: ", end="")
chunk_size = 300
print(chunk_size)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=50)
splits = text_splitter.split_documents(docs)
# 4. 轉換成embedding,儲存進Chroma向量資料庫.
vectorstore = Chroma.from_documents(
documents=splits, embedding=embeddingmodel)
retriever = vectorstore.as_retriever()
# 5. 做成chain.
template = """使用以下的上下文來回答最後的問題。
如果你不知道答案,就直接說你不知道,不要編造答案。
最多用三句話,並保持回答簡明扼要。
回答結束時,總是要說「感謝提問!」
{context}
使用者提供的額外資訊:
{user_input}
"""
custom_rag_prompt = PromptTemplate.from_template(template)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "user_input": lambda x: x}
| custom_rag_prompt
| model
| StrOutputParser()
)
# 6. 呼叫
result = rag_chain.invoke("新增哪6棟摩天大樓?")
print(result)
文件長度: 3569
chunk長度: 300
信义计划区域的新建六栋摩天大楼分别是:台北天空塔、四季酒店、富邦A25、富邦D1、南山A26和南山A21。南山A21预计最快在2028年完工。感謝提問!

